
OpenAI afirma: modelos de IA já fazem várias tarefas humanas no mesmo nível
Nesta quinta-feira (25), a OpenAI liberou novo benchmark que testa o desempenho dos modelos de inteligência artificial (IA) da desenvolvedora do ChatGPT em comparação a trabalhadores humanos. O teste foi realizado em uma ampla gama de setores e indústrias.
O teste, chamado de GDPval, trata-se de uma tentativa inicial de compreender o quão perto seus sistemas estão de superar os humanos em trabalhos economicamente valorizados, algo peça-chave para a missão da empresa de Sam Altman para chegar na tão sonhada inteligência artificial geral (IAG).
Segundo a startup, o GPT-5 e o Claude Opus 4.1, da Anthropic, “estão chegando perto da qualidade laboral executada pelos especialistas da indústria”.

Contudo, como frisa o TechCrunch, isso não quer dizer que os modelos de IA da Open AI nos substituirão em nossos postos de trabalho logo de cara.
Apesar de previsões de CEOs do setor de que a IA vai tomar os trabalhos das pessoas em poucos anos, a dona do ChatGPT admite que o GDPval, atualmente, cobre limitada quantidade de tarefas laborais realizadas por nós no dia a dia. Mas esta é uma das mais recentes formas pelas quais a OpenAI está medindo o progresso de sua IA rumo a este marco.
Como é balizado o teste de benchmark da OpenAI
- O GDPval é baseado em nove setores da indústria que mais contribuem com o Produto Interno Bruto (PIB) dos Estados Unidos;
- Isso inclui áreas, como saúde, financeiro, manufatureiro e governo;
- O teste analisa o desempenho de uma IA em 44 ocupações selecionadas entre os setores citados, indo desde engenheiros de software a enfermeiras e jornalistas;
- Na primeira versão do teste, batizada de GDPval-v0, a OpenAI pediu que profissionais experientes comparassem relatórios feitos por IA com os produzidos por humanos e, depois, que escolhessem os melhores;
- Um exemplo: um dos prompts solicitou que banqueiros de investimentos criassem um cenário competitivo para a mobilidade de último quilômetro (campo fundamental da cadeia de suprimentos) e os comparassem com os da IA;
- Entao, a startup calculou a média da “taxa de vitória” de uma IA em comparação com os relatórios de humanos em todas 44 funções testadas.
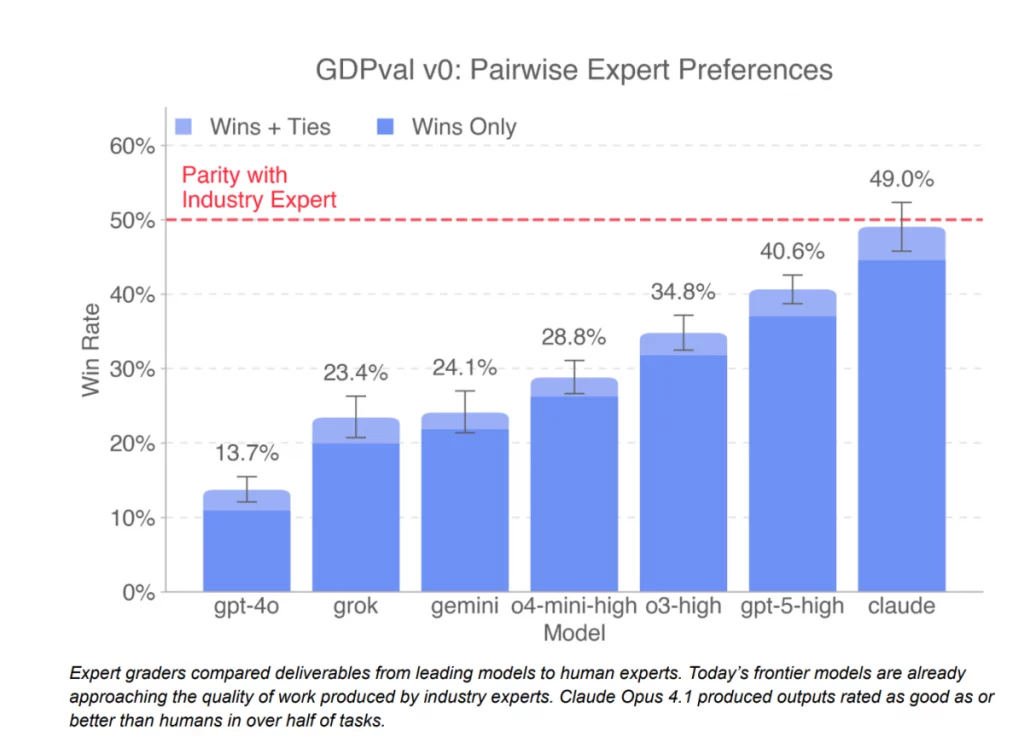
No teste do GPT-5-high — versão aprimorada do GPT-5 com mais poder computacional —, a OpenAI afirma que o modelo foi classificado como igual ou melhor que especialistas dos setores avaliados em 40,6% do tempo.
Já o Claude Opus 4.1, da Anthropic, foi classificado com melhor ou igual aos especialistas humanos em 49% das vezes, sendo, portanto, superior ao de sua concorrente. Contudo, a OpenAI opina que a porcentagem do Claude foi superior por conta de o modelo da Anthropic preferir criar gráficos mais agradáveis do que focar no puro desempenho.
Leia mais:

Futuro dessas avaliações
Mas o TechCrunch lembra, contudo, que muitos profissionais humanos fazem muito além do que apenas enviar relatórios para a chefia — que é o que o GDPval-v0 foi criado para testar. Sendo assim, a OpenAI reconhece essa situação e diz estar planejando criar testes mais robustos e que possam avaliar mais setores da indústria e fluxos de trabalho.
Ainda assim, expõe o portal, a indústria enxerga o progresso do GDPval como notável. Isso pode ser visto em entrevista do site com o economista-chefe da OpenAI, Dr. Aaron Chatterji, que afirmou que os resultados do teste sugerem que as pessoas nas funções analisadas podem, agora, usar os modelos de IA nessas tarefas, otimizando seu tempo e utilizando-o em tarefas mais importantes.
“[Por conta de] o modelo estar ficando bom em algumas dessas tarefas, as pessoas que atuam nessas funções podem, agora, usar o modelo, incrementando conforme sua capacidade melhora, de modo a diminuir a carga de trabalho e, potencialmente, mexer com coisas de maior valor”, disse.
Já a chefe das avaliações, Tejal Patwardhan, disse ao TechCrunch que ela foi encorajada pelo nível de progresso do GDPval. O modelo GPT-4, também da OpenAI, marcou apenas 13,7% (vence e empata quando enfrenta humanos) — ele foi lançado há cerca de 15 meses. Já o GPT-5 marca quase o triplo disso, marca que Patwardhan espera permanecer.
Outros benchmarks que estudam IA vs. humanos
A indústria do Vale do Silício possui várias opções de benchmarks que podem medir o progresso de suas IAs e avaliar se um dado modelo é o estado da arte (revisão sistemática e crítica da produção científica sobre um determinado tema, que visa identificar o nível mais alto de conhecimento alcançado em uma área até um dado momento). Entre os principais, estão o AIME 2025 (que testa problemas matemáticos competitivos) e o GPQA Diamond (que avalia questões científicas ao nível PhD).
Todavia, várias IAs estão próximas da saturação nesses benchmarks, e muitos pesquisadores do ramo citaram a necessidade de se criar melhores testes que possam medir a proficiência dos modelos em tarefas realizadas no mundo real.
Benchmarks como o GDPval têm o potencial de serem cada vez mais importantes nesse debate, enquanto a OpenAI apoia a ideia de que seus modelos de IA têm valor para uma grande quantidade de setores.

Só que, talvez, a startup — que visa deixar de ser uma organização sem fins lucrativos, algo que vem sendo tema de polêmica com outros grandes players da indústria — precise criar um teste que ateste, sem sombra de dúvidas, que suas IAs conseguem nos superar.
O post OpenAI afirma: modelos de IA já fazem várias tarefas humanas no mesmo nível apareceu primeiro em Olhar Digital.
source https://olhardigital.com.br/2025/09/25/pro/openai-afirma-gpt-5-faz-varias-tarefas-humanas-no-mesmo-nivel/